Compressing Feature Space for Classification Using PCA

In this project, we use Principal Component Analysis (PCA) to compress 100 unlabelled, sparse features into a more manageable number for classifying buyers of Ed Sheeran’s latest album.
Some Context
Our client is looking to promote Ed Sheeran’s new album - and want to be both targeted with their customer communications, and as efficient as possible with their marketing budget. As a proof-of-concept, they would like us to build a classification model for customers who purchased Ed’s last album based upon a small sample of listening data they have acquired for some of their customers at that time.
If we can do this successfully, they will look to purchase up-to-date listening data, apply the model, and use the predicted probabilities to promote to customers who are most likely to purchase.
Approach
The sample data is short but wide. It contains only 356 customers, but for each, columns that represent the percentage of historical listening time allocated to each of 100 artists. On top of these, the 100 columns do not contain the artist in question, instead being labelled artist1, artist2 etc.
So, we will need to compress this data of 100 inputs to a manageable number of components, so we can apply a classification model and do some predictions.
More details on the project can be found in the Jupyter Notebook here: Principal Component Analysis
Results
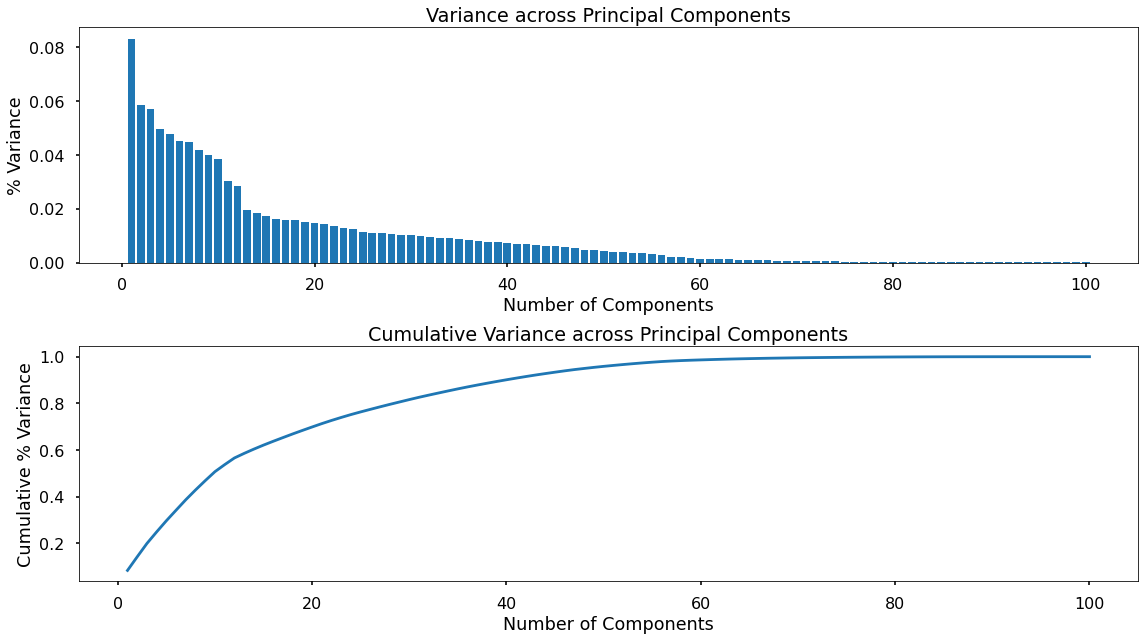
Based upon an analysis of variance vs. components - we made a call to keep 75% of the variance of the initial feature set, which meant we dropped the number of features from 100 down to 24. Now that’s a real insight!
Using these 24 components, we trained a Random Forest Classifier which is able to predict customers that would purchase Ed Sheeran’s last album with a Classification Accuracy of 93%.
