Predicting Customer Loyalty Using ML

The goal for the project is to build a model that would accurately predict the customers that would sign up for our client’s delivery club services. We use different classification algorithms to perform this task and understand what the main drivers are.
- Project Overview
- Data Overview
- Modelling Overview
- Linear Regression
- Decision Tree
- Random Forest
- Modelling Summary
- Predicting Missing Loyalty Scores
- Growth & Next Steps
Project Overview
Context
Our client, a grocery retailer, hired a market research consultancy to append market level customer loyalty information to the database. However, only around 50% of the client’s customer base could be tagged, thus the other half did not have this information present.
The overall aim of this work is to accurately predict the loyalty score for those customers who could not be tagged, enabling our client a clear understanding of true customer loyalty, regardless of total spend volume - and allowing for more accurate and relevant customer tracking, targeting, and comms.
To achieve this, we looked to build out a predictive model that will find relationships between customer metrics and loyalty score for those customers who were tagged, and use this to predict the loyalty score metric for those who were not.
Actions
We firstly needed to compile the necessary data from tables in the database, gathering key customer metrics that may help predict loyalty score, appending on the dependent variable, and separating out those who did and did not have this dependent variable present.
As we are predicting a numeric output, we tested three regression modelling approaches, namely:
- Linear Regression
- Decision Tree
- Random Forest
Results
Our testing found that the Random Forest had the highest predictive accuracy.
Metric 1: Adjusted R-Squared (Test Set)
- Random Forest = 0.955
- Decision Tree = 0.886
- Linear Regression = 0.754
Metric 2: R-Squared (K-Fold Cross Validation, k = 4)
- Random Forest = 0.925
- Decision Tree = 0.871
- Linear Regression = 0.853
As the most important outcome for this project was predictive accuracy, rather than explicitly understanding weighted drivers of prediction, we chose the Random Forest as the model to use for making predictions on the customers who were missing the loyalty score metric.
Growth/Next Steps
While predictive accuracy was relatively high - other modelling approaches could be tested, especially those somewhat similar to Random Forest, for example XGBoost, LightGBM to see if even more accuracy could be gained.
From a data point of view, further variables could be collected, and further feature engineering could be undertaken to ensure that we have as much useful information available for predicting customer loyalty
Key Definition
The loyalty score metric measures the % of grocery spend (market level) that each customer allocates to the client vs. all of the competitors.
Example 1: Customer X has a total grocery spend of $100 and all of this is spent with our client. Customer X has a loyalty score of 1.0
Example 2: Customer Y has a total grocery spend of $200 but only 20% is spent with our client. The remaining 80% is spend with competitors. Customer Y has a customer loyalty score of 0.2
___
Data Overview
We will be predicting the loyalty_score metric. This metric exists (for half of the customer base) in the loyalty_scores table of the client database.
The key variables hypothesised to predict the missing loyalty scores will come from the client database, namely the transactions table, the customer_details table, and the product_areas table.
Using pandas in Python, we merged these tables together for all customers, creating a single dataset that we can use for modelling.
# import required packages
import pandas as pd
import pickle
# import required data tables
loyalty_scores = ...
customer_details = ...
transactions = ...
# merge loyalty score data and customer details data, at customer level
data_for_regression = pd.merge(customer_details, loyalty_scores, how = "left", on = "customer_id")
# aggregate sales data from transactions table
sales_summary = transactions.groupby("customer_id").agg({"sales_cost" : "sum",
"num_items" : "sum",
"transaction_id" : "nunique",
"product_area_id" : "nunique"}).reset_index()
# rename columns for clarity
sales_summary.columns = ["customer_id", "total_sales", "total_items", "transaction_count", "product_area_count"]
# engineer an average basket value column for each customer
sales_summary["average_basket_value"] = sales_summary["total_sales"] / sales_summary["transaction_count"]
# merge the sales summary with the overall customer data
data_for_regression = pd.merge(data_for_regression, sales_summary, how = "inner", on = "customer_id")
# split out data for modelling (loyalty score is present)
regression_modelling = data_for_regression.loc[data_for_regression["customer_loyalty_score"].notna()]
# split out data for scoring post-modelling (loyalty score is missing)
regression_scoring = data_for_regression.loc[data_for_regression["customer_loyalty_score"].isna()]
# for scoring set, drop the loyalty score column (as it is blank/redundant)
regression_scoring.drop(["customer_loyalty_score"], axis = 1, inplace = True)
# save our datasets for future use
pickle.dump(regression_modelling, open("data/customer_loyalty_modelling.p", "wb"))
pickle.dump(regression_scoring, open("data/customer_loyalty_scoring.p", "wb"))
After this data pre-processing in Python, we have a dataset for modelling that contains the following fields…
| Variable Name | Variable Type | Description |
|---|---|---|
| loyalty_score | Dependent | The % of total grocery spend that each customer allocates to ABC Grocery vs. competitors |
| distance_from_store | Independent | “The distance in miles from the customers home address, and the store” |
| gender | Independent | The gender provided by the customer |
| credit_score | Independent | The customers most recent credit score |
| total_sales | Independent | Total spend by the customer in ABC Grocery within the latest 6 months |
| total_items | Independent | Total products purchased by the customer in ABC Grocery within the latest 6 months |
| transaction_count | Independent | Total unique transactions made by the customer in ABC Grocery within the latest 6 months |
| product_area_count | Independent | The number of product areas within ABC Grocery the customers has shopped into within the latest 6 months |
| average_basket_value | Independent | The average spend per transaction for the customer in ABC Grocery within the latest 6 months |
Modelling Overview
We will build a model that looks to accurately predict the “loyalty_score” metric for those customers that were able to be tagged, based upon the customer metrics listed above.
If that can be achieved, we can use this model to predict the customer loyalty score for the customers that were unable to be tagged by the agency.
As we are predicting a numeric output, we tested three regression modelling approaches, namely:
- Linear Regression
- Decision Tree
- Random Forest
Linear Regression
We utlise the scikit-learn library within Python to model our data using Linear Regression. The code sections below are broken up into 4 key sections:
- Data Import
- Data Preprocessing
- Model Training
- Performance Assessment
Data Import
Since we saved our modelling data as a pickle file, we import it. We ensure we remove the id column, and we also ensure our data is shuffled.
# import required packages
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.metrics import r2_score
from sklearn.preprocessing import OneHotEncoder
from sklearn.feature_selection import RFECV
# import modelling data
data_for_model = pickle.load(open("data/customer_loyalty_modelling.p", "rb"))
# drop uneccessary columns
data_for_model.drop("customer_id", axis = 1, inplace = True)
# shuffle data
data_for_model = shuffle(data_for_model, random_state = 42)
Data Preprocessing
For Linear Regression we have certain data preprocessing steps that need to be addressed, including:
- Missing values in the data
- The effect of outliers
- Encoding categorical variables to numeric form
- Multicollinearity & Feature Selection
Missing Values
The number of missing values in the data was extremely low, so instead of applying any imputation (i.e. mean, most common value) we will just remove those rows
# remove rows where values are missing
data_for_model.isna().sum()
data_for_model.dropna(how = "any", inplace = True)
Outliers
The ability for a Linear Regression model to generalise well across all data can be hampered if there are outliers present. There is no right or wrong way to deal with outliers, but it is always something worth very careful consideration - just because a value is high or low, does not necessarily mean it should not be there!
In this code section, we use .describe() from Pandas to investigate the spread of values for each of our predictors. The results of this can be seen in the table below.
| metric | distance_from_store | credit_score | total_sales | total_items | transaction_count | product_area_count | average_basket_value |
|---|---|---|---|---|---|---|---|
| mean | 2.02 | 0.60 | 1846.50 | 278.30 | 44.93 | 4.31 | 36.78 |
| std | 2.57 | 0.10 | 1767.83 | 214.24 | 21.25 | 0.73 | 19.34 |
| min | 0.00 | 0.26 | 45.95 | 10.00 | 4.00 | 2.00 | 9.34 |
| 25% | 0.71 | 0.53 | 942.07 | 201.00 | 41.00 | 4.00 | 22.41 |
| 50% | 1.65 | 0.59 | 1471.49 | 258.50 | 50.00 | 4.00 | 30.37 |
| 75% | 2.91 | 0.66 | 2104.73 | 318.50 | 53.00 | 5.00 | 47.21 |
| max | 44.37 | 0.88 | 9878.76 | 1187.00 | 109.00 | 5.00 | 102.34 |
Based on this investigation, we see some max column values for several variables to be much higher than the median value.
This is for columns distance_from_store, total_sales, and total_items
For example, the median distance_to_store is 1.645 miles, but the maximum is over 44 miles!
Because of this, we apply some outlier removal in order to facilitate generalisation across the full dataset.
We do this using the “boxplot approach” where we remove any rows where the values within those columns are outside of the interquartile range multiplied by 2.
outlier_investigation = data_for_model.describe()
outlier_columns = ["distance_from_store", "total_sales", "total_items"]
# boxplot approach
for column in outlier_columns:
lower_quartile = data_for_model[column].quantile(0.25)
upper_quartile = data_for_model[column].quantile(0.75)
iqr = upper_quartile - lower_quartile
iqr_extended = iqr * 2
min_border = lower_quartile - iqr_extended
max_border = upper_quartile + iqr_extended
outliers = data_for_model[(data_for_model[column] < min_border) | (data_for_model[column] > max_border)].index
print(f"{len(outliers)} outliers detected in column {column}")
data_for_model.drop(outliers, inplace = True)
Split Out Data For Modelling
In the next code block we do two things, we firstly split our data into an X object which contains only the predictor variables, and a y object that contains only our dependent variable.
Once we have done this, we split our data into training and test sets to ensure we can fairly validate the accuracy of the predictions on data that was not used in training. In this case, we have allocated 80% of the data for training, and the remaining 20% for validation.
# split data into X and y objects for modelling
X = data_for_model.drop(["customer_loyalty_score"], axis = 1)
y = data_for_model["customer_loyalty_score"]
# split out training & test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
Categorical Predictor Variables
In our dataset, we have one categorical variable gender which has values of “M” for Male, “F” for Female, and “U” for Unknown.
The Linear Regression algorithm can’t deal with data in this format as it can’t assign any numerical meaning to it when looking to assess the relationship between the variable and the dependent variable.
As gender doesn’t have any explicit order to it, in other words, Male isn’t higher or lower than Female and vice versa - one appropriate approach is to apply One Hot Encoding to the categorical column.
One Hot Encoding can be thought of as a way to represent categorical variables as binary vectors, in other words, a set of new columns for each categorical value with either a 1 or a 0 saying whether that value is true or not for that observation. These new columns would go into our model as input variables, and the original column is discarded.
We also drop one of the new columns using the parameter drop = “first”. We do this to avoid the dummy variable trap where our newly created encoded columns perfectly predict each other - and we run the risk of breaking the assumption that there is no multicollinearity, a requirement or at least an important consideration for some models, Linear Regression being one of them! Multicollinearity occurs when two or more input variables are highly correlated with each other, it is a scenario we attempt to avoid as in short, while it won’t neccessarily affect the predictive accuracy of our model, it can make it difficult to trust the statistics around how well the model is performing, and how much each input variable is truly having.
In the code, we also make sure to apply fit_transform to the training set, but only transform to the test set. This means the One Hot Encoding logic will learn and apply the “rules” from the training data, but only apply them to the test data. This is important in order to avoid data leakage where the test set learns information about the training data, and means we can’t fully trust model performance metrics!
For ease, after we have applied One Hot Encoding, we turn our training and test objects back into Pandas Dataframes, with the column names applied.
# list of categorical variables that need encoding
categorical_vars = ["gender"]
# instantiate OHE class
one_hot_encoder = OneHotEncoder(sparse=False, drop = "first")
# apply OHE
X_train_encoded = one_hot_encoder.fit_transform(X_train[categorical_vars])
X_test_encoded = one_hot_encoder.transform(X_test[categorical_vars])
# extract feature names for encoded columns
encoder_feature_names = one_hot_encoder.get_feature_names_out(categorical_vars)
# turn objects back to pandas dataframe
X_train_encoded = pd.DataFrame(X_train_encoded, columns = encoder_feature_names)
X_train = pd.concat([X_train.reset_index(drop=True), X_train_encoded.reset_index(drop=True)], axis = 1)
X_train.drop(categorical_vars, axis = 1, inplace = True)
X_test_encoded = pd.DataFrame(X_test_encoded, columns = encoder_feature_names)
X_test = pd.concat([X_test.reset_index(drop=True), X_test_encoded.reset_index(drop=True)], axis = 1)
X_test.drop(categorical_vars, axis = 1, inplace = True)
Feature Selection
Feature Selection is the process used to select the input variables that are most important to your Machine Learning task. It can be a very important addition or at least, consideration, in certain scenarios. The potential benefits of Feature Selection are:
- Improved Model Accuracy - eliminating noise can help true relationships stand out
- Lower Computational Cost - our model becomes faster to train, and faster to make predictions
- Explainability - understanding & explaining outputs for stakeholder & customers becomes much easier
There are many, many ways to apply Feature Selection. These range from simple methods such as a Correlation Matrix showing variable relationships, to Univariate Testing which helps us understand statistical relationships between variables, and then to even more powerful approaches like Recursive Feature Elimination (RFE) which is an approach that starts with all input variables, and then iteratively removes those with the weakest relationships with the output variable.
For our task we applied a variation of Reursive Feature Elimination called Recursive Feature Elimination With Cross Validation (RFECV) where we split the data into many “chunks” and iteratively trains & validates models on each “chunk” seperately. This means that each time we assess different models with different variables included, or eliminated, the algorithm also knows how accurate each of those models was. From the suite of model scenarios that are created, the algorithm can determine which provided the best accuracy, and thus can infer the best set of input variables to use!
# instantiate RFECV & the model type to be utilised
regressor = LinearRegression()
feature_selector = RFECV(regressor)
# fit RFECV onto our training & test data
fit = feature_selector.fit(X_train,y_train)
# extract & print the optimal number of features
optimal_feature_count = feature_selector.n_features_
print(f"Optimal number of features: {optimal_feature_count}")
# limit our training & test sets to only include the selected variables
X_train = X_train.loc[:, feature_selector.get_support()]
X_test = X_test.loc[:, feature_selector.get_support()]
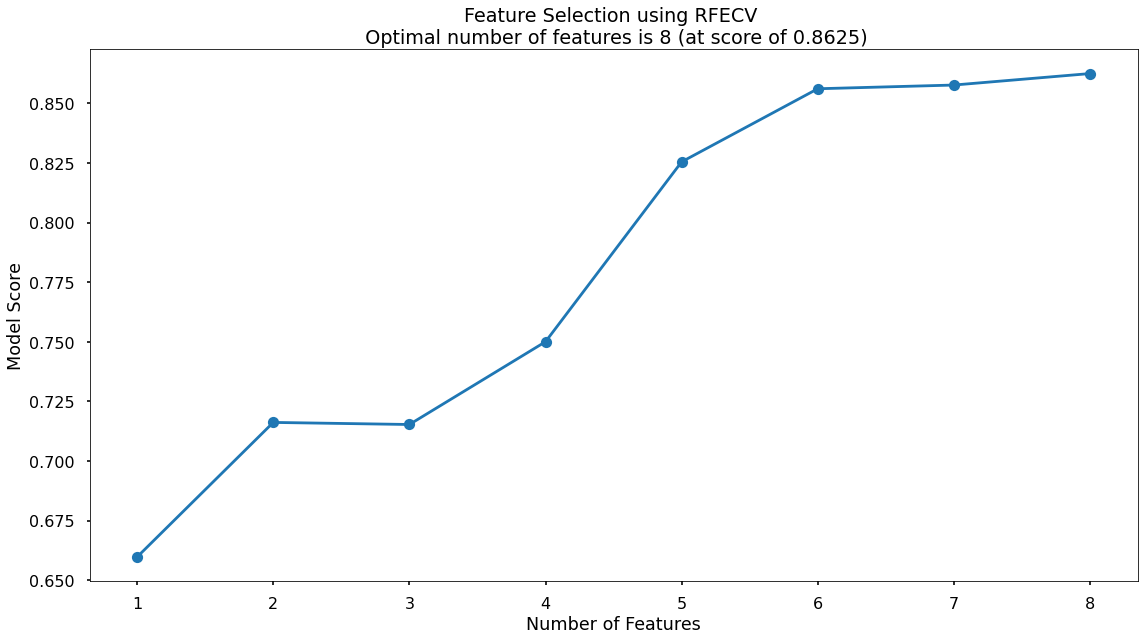
The below code then produces a plot that visualises the cross-validated accuracy with each potential number of features
plt.style.use('seaborn-poster')
plt.plot(range(1, len(fit.cv_results_['mean_test_score']) + 1), fit.cv_results_['mean_test_score'], marker = "o")
plt.ylabel("Model Score")
plt.xlabel("Number of Features")
plt.title(f"Feature Selection using RFE \n Optimal number of features is {optimal_feature_count} (at score of {round(max(fit.cv_results_['mean_test_score']),4)})")
plt.tight_layout()
plt.show()
This creates the below plot, which shows us that the highest cross-validated accuracy (0.8635) is actually when we include all eight of our original input variables. This is marginally higher than 6 included variables, and 7 included variables. We will continue on with all 8!
Model Training
Instantiating and training our Linear Regression model is done using the below code
# instantiate our model object
regressor = LinearRegression()
# fit our model using our training & test sets
regressor.fit(X_train, y_train)
Model Performance Assessment
Predict On The Test Set
To assess how well our model is predicting on new data - we use the trained model object (here called regressor) and ask it to predict the loyalty_score variable for the test set
# predict on the test set
y_pred = regressor.predict(X_test)
Calculate R-Squared
R-Squared is a metric that shows the percentage of variance in our output variable y that is being explained by our input variable(s) x. It is a value that ranges between 0 and 1, with a higher value showing a higher level of explained variance. Another way of explaining this would be to say that, if we had an r-squared score of 0.8 it would suggest that 80% of the variation of our output variable is being explained by our input variables - and something else, or some other variables must account for the other 20%
To calculate r-squared, we use the following code where we pass in our predicted outputs for the test set (y_pred), as well as the actual outputs for the test set (y_test)
# calculate r-squared for our test set predictions
r_squared = r2_score(y_test, y_pred)
print(r_squared)
The resulting r-squared score from this is 0.78
Calculate Cross Validated R-Squared
An even more powerful and reliable way to assess model performance is to utilise Cross Validation.
Instead of simply dividing our data into a single training set, and a single test set, with Cross Validation we break our data into a number of “chunks” and then iteratively train the model on all but one of the “chunks”, test the model on the remaining “chunk” until each has had a chance to be the test set.
The result of this is that we are provided a number of test set validation results - and we can take the average of these to give a much more robust & reliable view of how our model will perform on new, un-seen data!
In the code below, we put this into place. We first specify that we want 4 “chunks” and then we pass in our regressor object, training set, and test set. We also specify the metric we want to assess with, in this case, we stick with r-squared.
Finally, we take a mean of all four test set results.
# calculate the mean cross validated r-squared for our test set predictions
cv = KFold(n_splits = 4, shuffle = True, random_state = 42)
cv_scores = cross_val_score(regressor, X_train, y_train, cv = cv, scoring = "r2")
cv_scores.mean()
The mean cross-validated r-squared score from this is 0.853
Calculate Adjusted R-Squared
When applying Linear Regression with multiple input variables, the r-squared metric on it’s own can end up being an overinflated view of goodness of fit. This is because each input variable will have an additive effect on the overall r-squared score. In other words, every input variable added to the model increases the r-squared value, and never decreases it, even if the relationship is by chance.
Adjusted R-Squared is a metric that compensates for the addition of input variables, and only increases if the variable improves the model above what would be obtained by probability. It is best practice to use Adjusted R-Squared when assessing the results of a Linear Regression with multiple input variables, as it gives a fairer perception the fit of the data.
# calculate adjusted r-squared for our test set predictions
num_data_points, num_input_vars = X_test.shape
adjusted_r_squared = 1 - (1 - r_squared) * (num_data_points - 1) / (num_data_points - num_input_vars - 1)
print(adjusted_r_squared)
The resulting adjusted r-squared score from this is 0.754 which as expected, is slightly lower than the score we got for r-squared on it’s own.
Model Summary Statistics
Although our overall goal for this project is predictive accuracy, rather than an explcit understanding of the relationships of each of the input variables and the output variable, it is always interesting to look at the summary statistics for these.
# extract model coefficients
coefficients = pd.DataFrame(regressor.coef_)
input_variable_names = pd.DataFrame(X_train.columns)
summary_stats = pd.concat([input_variable_names,coefficients], axis = 1)
summary_stats.columns = ["input_variable", "coefficient"]
# extract model intercept
regressor.intercept_
The information from that code block can be found in the table below:
| input_variable | coefficient |
|---|---|
| intercept | 0.516 |
| distance_from_store | -0.201 |
| credit_score | -0.028 |
| total_sales | 0.000 |
| total_items | 0.001 |
| transaction_count | -0.005 |
| product_area_count | 0.062 |
| average_basket_value | -0.004 |
| gender_M | -0.013 |
The coefficient value for each of the input variables, along with that of the intercept would make up the equation for the line of best fit for this particular model (or more accurately, in this case it would be the plane of best fit, as we have multiple input variables).
For each input variable, the coefficient value we see above tells us, with everything else staying constant how many units the output variable (loyalty score) would change with a one unit change in this particular input variable.
To provide an example of this - in the table above, we can see that the distance_from_store input variable has a coefficient value of -0.201. This is saying that loyalty_score decreases by 0.201 (or 20% as loyalty score is a percentage, or at least a decimal value between 0 and 1) for every additional mile that a customer lives from the store. This makes intuitive sense, as customers who live a long way from this store, most likely live near another store where they might do some of their shopping as well, whereas customers who live near this store, probably do a greater proportion of their shopping at this store…and hence have a higher loyalty score!
Decision Tree
We will again utlise the scikit-learn library within Python to model our data using a Decision Tree. The code sections below are broken up into 4 key sections:
- Data Import
- Data Preprocessing
- Model Training
- Performance Assessment
Data Import
Since we saved our modelling data as a pickle file, we import it. We ensure we remove the id column, and we also ensure our data is shuffled.
# import required packages
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.metrics import r2_score
from sklearn.preprocessing import OneHotEncoder
# import modelling data
data_for_model = pickle.load(open("data/customer_loyalty_modelling.p", "rb"))
# drop uneccessary columns
data_for_model.drop("customer_id", axis = 1, inplace = True)
# shuffle data
data_for_model = shuffle(data_for_model, random_state = 42)
Data Preprocessing
While Linear Regression is susceptible to the effects of outliers, and highly correlated input variables - Decision Trees are not, so the required preprocessing here is lighter. We still however will put in place logic for:
- Missing values in the data
- Encoding categorical variables to numeric form
Missing Values
The number of missing values in the data was extremely low, so instead of applying any imputation (i.e. mean, most common value) we will just remove those rows
# remove rows where values are missing
data_for_model.isna().sum()
data_for_model.dropna(how = "any", inplace = True)
Split Out Data For Modelling
In exactly the same way we did for Linear Regression, in the next code block we do two things, we firstly split our data into an X object which contains only the predictor variables, and a y object that contains only our dependent variable.
Once we have done this, we split our data into training and test sets to ensure we can fairly validate the accuracy of the predictions on data that was not used in training. In this case, we have allocated 80% of the data for training, and the remaining 20% for validation.
# split data into X and y objects for modelling
X = data_for_model.drop(["customer_loyalty_score"], axis = 1)
y = data_for_model["customer_loyalty_score"]
# split out training & test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
Categorical Predictor Variables
In our dataset, we have one categorical variable gender which has values of “M” for Male, “F” for Female, and “U” for Unknown.
Just like the Linear Regression algorithm, the Decision Tree cannot deal with data in this format as it can’t assign any numerical meaning to it when looking to assess the relationship between the variable and the dependent variable.
As gender doesn’t have any explicit order to it, in other words, Male isn’t higher or lower than Female and vice versa - we would again apply One Hot Encoding to the categorical column.
# list of categorical variables that need encoding
categorical_vars = ["gender"]
# instantiate OHE class
one_hot_encoder = OneHotEncoder(sparse=False, drop = "first")
# apply OHE
X_train_encoded = one_hot_encoder.fit_transform(X_train[categorical_vars])
X_test_encoded = one_hot_encoder.transform(X_test[categorical_vars])
# extract feature names for encoded columns
encoder_feature_names = one_hot_encoder.get_feature_names_out(categorical_vars)
# turn objects back to pandas dataframe
X_train_encoded = pd.DataFrame(X_train_encoded, columns = encoder_feature_names)
X_train = pd.concat([X_train.reset_index(drop=True), X_train_encoded.reset_index(drop=True)], axis = 1)
X_train.drop(categorical_vars, axis = 1, inplace = True)
X_test_encoded = pd.DataFrame(X_test_encoded, columns = encoder_feature_names)
X_test = pd.concat([X_test.reset_index(drop=True), X_test_encoded.reset_index(drop=True)], axis = 1)
X_test.drop(categorical_vars, axis = 1, inplace = True)
Model Training
Instantiating and training our Decision Tree model is done using the below code. We use the random_state parameter to ensure we get reproducible results, and this helps us understand any improvements in performance with changes to model hyperparameters.
# instantiate our model object
regressor = DecisionTreeRegressor(random_state = 42)
# fit our model using our training & test sets
regressor.fit(X_train, y_train)
Model Performance Assessment
Predict On The Test Set
To assess how well our model is predicting on new data - we use the trained model object (here called regressor) and ask it to predict the loyalty_score variable for the test set
# predict on the test set
y_pred = regressor.predict(X_test)
Calculate R-Squared
To calculate r-squared, we use the following code where we pass in our predicted outputs for the test set (y_pred), as well as the actual outputs for the test set (y_test)
# calculate r-squared for our test set predictions
r_squared = r2_score(y_test, y_pred)
print(r_squared)
The resulting r-squared score from this is 0.898
Calculate Cross Validated R-Squared
As we did when testing Linear Regression, we will again utilise Cross Validation.
Instead of simply dividing our data into a single training set, and a single test set, with Cross Validation we break our data into a number of “chunks” and then iteratively train the model on all but one of the “chunks”, test the model on the remaining “chunk” until each has had a chance to be the test set.
The result of this is that we are provided a number of test set validation results - and we can take the average of these to give a much more robust & reliable view of how our model will perform on new, un-seen data!
In the code below, we put this into place. We again specify that we want 4 “chunks” and then we pass in our regressor object, training set, and test set. We also specify the metric we want to assess with, in this case, we stick with r-squared.
Finally, we take a mean of all four test set results.
# calculate the mean cross validated r-squared for our test set predictions
cv = KFold(n_splits = 4, shuffle = True, random_state = 42)
cv_scores = cross_val_score(regressor, X_train, y_train, cv = cv, scoring = "r2")
cv_scores.mean()
The mean cross-validated r-squared score from this is 0.871 which is slighter higher than we saw for Linear Regression.
Calculate Adjusted R-Squared
Just like we did with Linear Regression, we will also calculate the Adjusted R-Squared which compensates for the addition of input variables, and only increases if the variable improves the model above what would be obtained by probability.
# calculate adjusted r-squared for our test set predictions
num_data_points, num_input_vars = X_test.shape
adjusted_r_squared = 1 - (1 - r_squared) * (num_data_points - 1) / (num_data_points - num_input_vars - 1)
print(adjusted_r_squared)
The resulting adjusted r-squared score from this is 0.887 which as expected, is slightly lower than the score we got for r-squared on it’s own.
Decision Tree Regularisation
Decision Tree’s can be prone to over-fitting, in other words, without any limits on their splitting, they will end up learning the training data perfectly. We would much prefer our model to have a more generalised set of rules, as this will be more robust & reliable when making predictions on new data.
One effective method of avoiding this over-fitting, is to apply a max depth to the Decision Tree, meaning we only allow it to split the data a certain number of times before it is required to stop.
Unfortunately, we don’t necessarily know the best number of splits to use for this - so below we will loop over a variety of values and assess which gives us the best predictive performance!
# finding the best max_depth
# set up range for search, and empty list to append accuracy scores to
max_depth_list = list(range(1,9))
accuracy_scores = []
# loop through each possible depth, train and validate model, append test set accuracy
for depth in max_depth_list:
regressor = DecisionTreeRegressor(max_depth = depth, random_state = 42)
regressor.fit(X_train,y_train)
y_pred = regressor.predict(X_test)
accuracy = r2_score(y_test,y_pred)
accuracy_scores.append(accuracy)
# store max accuracy, and optimal depth
max_accuracy = max(accuracy_scores)
max_accuracy_idx = accuracy_scores.index(max_accuracy)
optimal_depth = max_depth_list[max_accuracy_idx]
# plot accuracy by max depth
plt.plot(max_depth_list,accuracy_scores)
plt.scatter(optimal_depth, max_accuracy, marker = "x", color = "red")
plt.title(f"Accuracy by Max Depth \n Optimal Tree Depth: {optimal_depth} (Accuracy: {round(max_accuracy,4)})")
plt.xlabel("Max Depth of Decision Tree")
plt.ylabel("Accuracy")
plt.tight_layout()
plt.show()
That code gives us the below plot - which visualises the results!
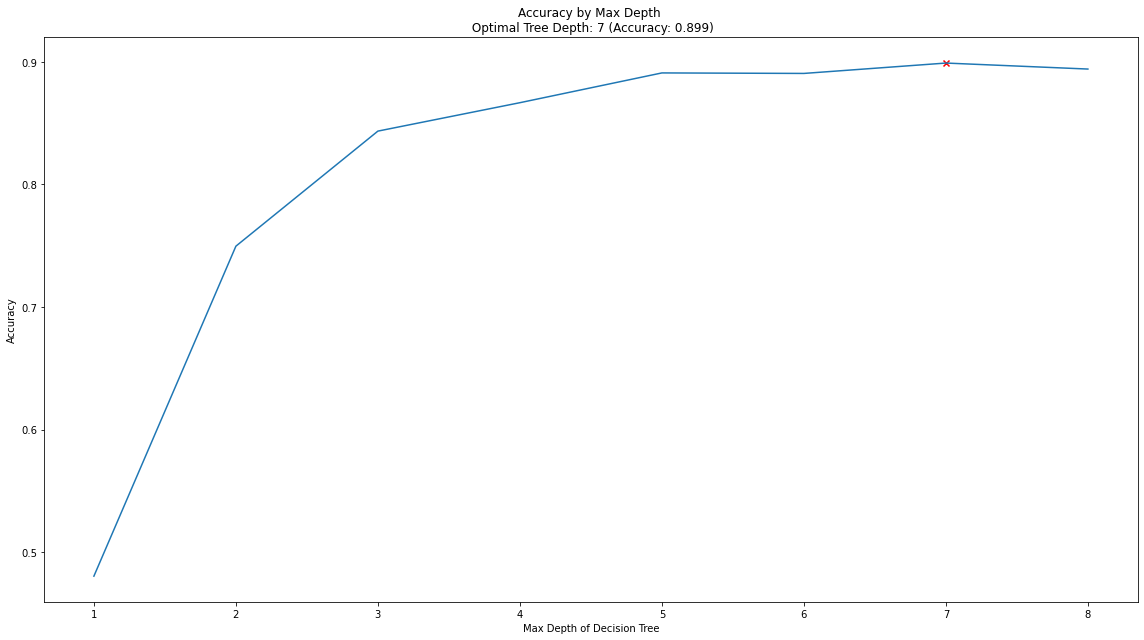
In the plot we can see that the maximum classification accuracy on the test set is found when applying a max_depth value of 7. However, we lose very little accuracy back to a value of 4, but this would result in a simpler model, that generalised even better on new data. We make the executive decision to re-train our Decision Tree with a maximum depth of 4!
Visualise Our Decision Tree
To see the decisions that have been made in the (re-fitted) tree, we can use the plot_tree functionality that we imported from scikit-learn. To do this, we use the below code:
# re-fit our model using max depth of 4
regressor = DecisionTreeRegressor(random_state = 42, max_depth = 4)
regressor.fit(X_train, y_train)
# plot the nodes of the decision tree
plt.figure(figsize=(25,15))
tree = plot_tree(regressor,
feature_names = X.columns,
filled = True,
rounded = True,
fontsize = 16)
That code gives us the below plot:
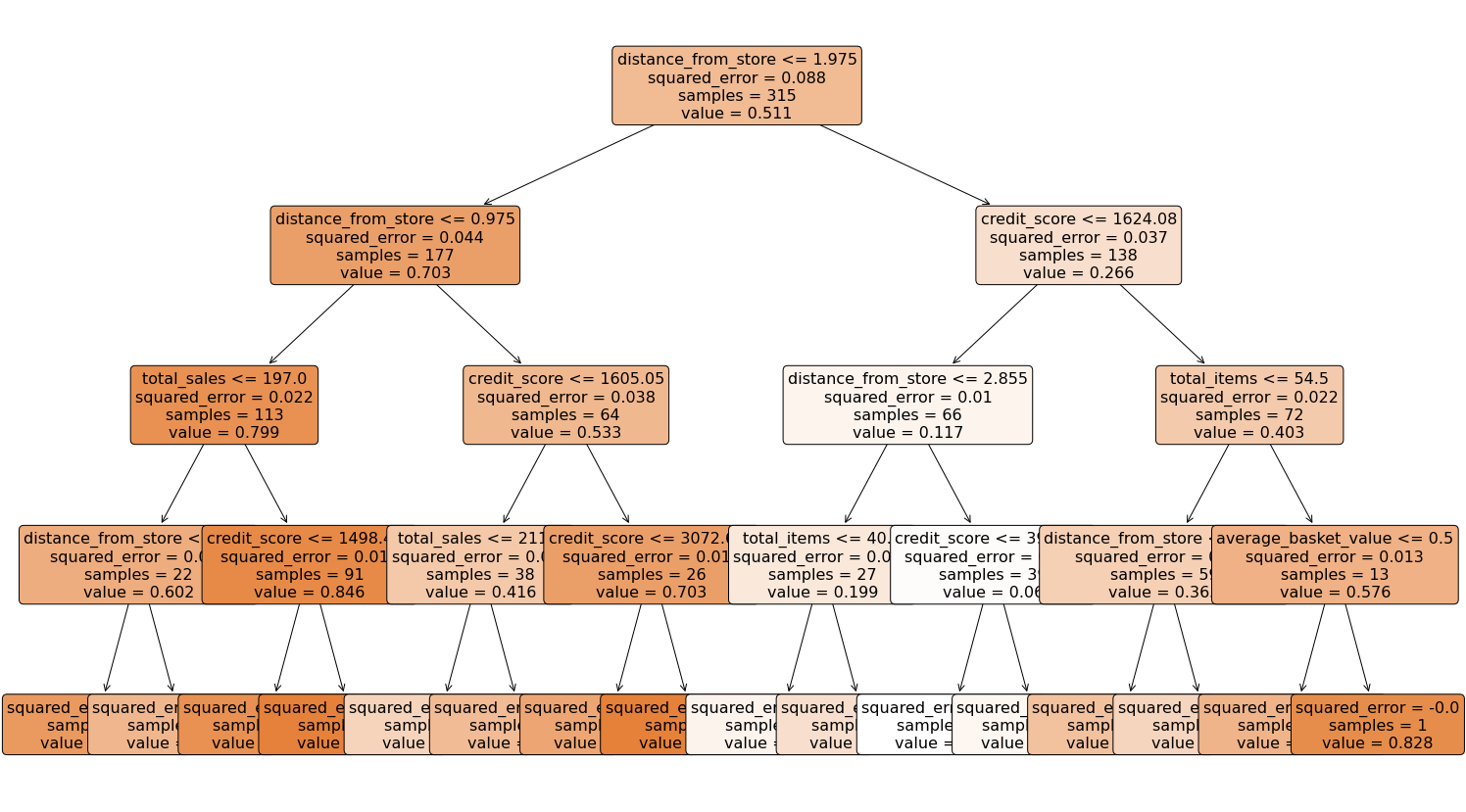
This is a very powerful visual, and one that can be shown to stakeholders in the business to ensure they understand exactly what is driving the predictions.
One interesting thing to note is that the very first split appears to be using the variable distance from store so it would seem that this is a very important variable when it comes to predicting loyalty!
Random Forest
We will again utlise the scikit-learn library within Python to model our data using a Random Forest. The code sections below are broken up into 4 key sections:
- Data Import
- Data Preprocessing
- Model Training
- Performance Assessment
Data Import
Again, since we saved our modelling data as a pickle file, we import it. We ensure we remove the id column, and we also ensure our data is shuffled.
# import required packages
import pandas as pd
import pickle
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.metrics import r2_score
from sklearn.preprocessing import OneHotEncoder
from sklearn.inspection import permutation_importance
# import modelling data
data_for_model = pickle.load(open("data/customer_loyalty_modelling.p", "rb"))
# drop uneccessary columns
data_for_model.drop("customer_id", axis = 1, inplace = True)
# shuffle data
data_for_model = shuffle(data_for_model, random_state = 42)
Data Preprocessing
While Linear Regression is susceptible to the effects of outliers, and highly correlated input variables - Random Forests, just like Decision Trees, are not, so the required preprocessing here is lighter. We still however will put in place logic for:
- Missing values in the data
- Encoding categorical variables to numeric form
Missing Values
The number of missing values in the data was extremely low, so instead of applying any imputation (i.e. mean, most common value) we will just remove those rows
# remove rows where values are missing
data_for_model.isna().sum()
data_for_model.dropna(how = "any", inplace = True)
Split Out Data For Modelling
In exactly the same way we did for Linear Regression, in the next code block we do two things, we firstly split our data into an X object which contains only the predictor variables, and a y object that contains only our dependent variable.
Once we have done this, we split our data into training and test sets to ensure we can fairly validate the accuracy of the predictions on data that was not used in training. In this case, we have allocated 80% of the data for training, and the remaining 20% for validation.
# split data into X and y objects for modelling
X = data_for_model.drop(["customer_loyalty_score"], axis = 1)
y = data_for_model["customer_loyalty_score"]
# split out training & test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
Categorical Predictor Variables
In our dataset, we have one categorical variable gender which has values of “M” for Male, “F” for Female, and “U” for Unknown.
Just like the Linear Regression algorithm, Random Forests cannot deal with data in this format as it can’t assign any numerical meaning to it when looking to assess the relationship between the variable and the dependent variable.
As gender doesn’t have any explicit order to it, in other words, Male isn’t higher or lower than Female and vice versa - we would again apply One Hot Encoding to the categorical column.
# list of categorical variables that need encoding
categorical_vars = ["gender"]
# instantiate OHE class
one_hot_encoder = OneHotEncoder(sparse=False, drop = "first")
# apply OHE
X_train_encoded = one_hot_encoder.fit_transform(X_train[categorical_vars])
X_test_encoded = one_hot_encoder.transform(X_test[categorical_vars])
# extract feature names for encoded columns
encoder_feature_names = one_hot_encoder.get_feature_names_out(categorical_vars)
# turn objects back to pandas dataframe
X_train_encoded = pd.DataFrame(X_train_encoded, columns = encoder_feature_names)
X_train = pd.concat([X_train.reset_index(drop=True), X_train_encoded.reset_index(drop=True)], axis = 1)
X_train.drop(categorical_vars, axis = 1, inplace = True)
X_test_encoded = pd.DataFrame(X_test_encoded, columns = encoder_feature_names)
X_test = pd.concat([X_test.reset_index(drop=True), X_test_encoded.reset_index(drop=True)], axis = 1)
X_test.drop(categorical_vars, axis = 1, inplace = True)
Model Training
Instantiating and training our Random Forest model is done using the below code. We use the random_state parameter to ensure we get reproducible results, and this helps us understand any improvements in performance with changes to model hyperparameters.
We leave the other parameters at their default values, meaning that we will just be building 100 Decision Trees in this Random Forest.
# instantiate our model object
regressor = RandomForestRegressor(random_state = 42)
# fit our model using our training & test sets
regressor.fit(X_train, y_train)
Model Performance Assessment
Predict On The Test Set
To assess how well our model is predicting on new data - we use the trained model object (here called regressor) and ask it to predict the loyalty_score variable for the test set
# predict on the test set
y_pred = regressor.predict(X_test)
Calculate R-Squared
To calculate r-squared, we use the following code where we pass in our predicted outputs for the test set (y_pred), as well as the actual outputs for the test set (y_test)
# calculate r-squared for our test set predictions
r_squared = r2_score(y_test, y_pred)
print(r_squared)
The resulting r-squared score from this is 0.957 - higher than both Linear Regression & the Decision Tree.
Calculate Cross Validated R-Squared
As we did when testing Linear Regression & our Decision Tree, we will again utilise Cross Validation (for more info on how this works, please refer to the Linear Regression section above)
# calculate the mean cross validated r-squared for our test set predictions
cv = KFold(n_splits = 4, shuffle = True, random_state = 42)
cv_scores = cross_val_score(regressor, X_train, y_train, cv = cv, scoring = "r2")
cv_scores.mean()
The mean cross-validated r-squared score from this is 0.923 which agian is higher than we saw for both Linear Regression & our Decision Tree.
Calculate Adjusted R-Squared
Just like we did with Linear Regression & our Decision Tree, we will also calculate the Adjusted R-Squared which compensates for the addition of input variables, and only increases if the variable improves the model above what would be obtained by probability.
# calculate adjusted r-squared for our test set predictions
num_data_points, num_input_vars = X_test.shape
adjusted_r_squared = 1 - (1 - r_squared) * (num_data_points - 1) / (num_data_points - num_input_vars - 1)
print(adjusted_r_squared)
The resulting adjusted r-squared score from this is 0.955 which as expected, is slightly lower than the score we got for r-squared on it’s own - but again higher than for our other models.
Feature Importance
In our Linear Regression model, to understand the relationships between input variables and our ouput variable, loyalty score, we examined the coefficients. With our Decision Tree we looked at what the earlier splits were. These allowed us some insight into which input variables were having the most impact.
Random Forests are an ensemble model, made up of many, many Decision Trees, each of which is different due to the randomness of the data being provided, and the random selection of input variables available at each potential split point.
Because of this, we end up with a powerful and robust model, but because of the random or different nature of all these Decision trees - the model gives us a unique insight into how important each of our input variables are to the overall model.
As we’re using random samples of data, and input variables for each Decision Tree - there are many scenarios where certain input variables are being held back and this enables us a way to compare how accurate the models predictions are if that variable is or isn’t present.
So, at a high level, in a Random Forest we can measure importance by asking How much would accuracy decrease if a specific input variable was removed or randomised?
If this decrease in performance, or accuracy, is large, then we’d deem that input variable to be quite important, and if we see only a small decrease in accuracy, then we’d conclude that the variable is of less importance.
At a high level, there are two common ways to tackle this. The first, often just called Feature Importance is where we find all nodes in the Decision Trees of the forest where a particular input variable is used to split the data and assess what the Mean Squared Error (for a Regression problem) was before the split was made, and compare this to the Mean Squared Error after the split was made. We can take the average of these improvements across all Decision Trees in the Random Forest to get a score that tells us how much better we’re making the model by using that input variable.
If we do this for each of our input variables, we can compare these scores and understand which is adding the most value to the predictive power of the model!
The other approach, often called Permutation Importance cleverly uses some data that has gone unused at when random samples are selected for each Decision Tree (this stage is called “bootstrap sampling” or “bootstrapping”)
These observations that were not randomly selected for each Decision Tree are known as Out of Bag observations and these can be used for testing the accuracy of each particular Decision Tree.
For each Decision Tree, all of the Out of Bag observations are gathered and then passed through. Once all of these observations have been run through the Decision Tree, we obtain an accuracy score for these predictions, which in the case of a regression problem could be Mean Squared Error or r-squared.
In order to understand the importance, we randomise the values within one of the input variables - a process that essentially destroys any relationship that might exist between that input variable and the output variable - and run that updated data through the Decision Tree again, obtaining a second accuracy score. The difference between the original accuracy and the new accuracy gives us a view on how important that particular variable is for predicting the output.
Permutation Importance is often preferred over Feature Importance which can at times inflate the importance of numerical features. Both are useful, and in most cases will give fairly similar results.
Let’s put them both in place, and plot the results…
# calculate feature importance
feature_importance = pd.DataFrame(regressor.feature_importances_)
feature_names = pd.DataFrame(X.columns)
feature_importance_summary = pd.concat([feature_names,feature_importance], axis = 1)
feature_importance_summary.columns = ["input_variable","feature_importance"]
feature_importance_summary.sort_values(by = "feature_importance", inplace = True)
# plot feature importance
plt.barh(feature_importance_summary["input_variable"],feature_importance_summary["feature_importance"])
plt.title("Feature Importance of Random Forest")
plt.xlabel("Feature Importance")
plt.tight_layout()
plt.show()
# calculate permutation importance
result = permutation_importance(regressor, X_test, y_test, n_repeats = 10, random_state = 42)
permutation_importance = pd.DataFrame(result["importances_mean"])
feature_names = pd.DataFrame(X.columns)
permutation_importance_summary = pd.concat([feature_names,permutation_importance], axis = 1)
permutation_importance_summary.columns = ["input_variable","permutation_importance"]
permutation_importance_summary.sort_values(by = "permutation_importance", inplace = True)
# plot permutation importance
plt.barh(permutation_importance_summary["input_variable"],permutation_importance_summary["permutation_importance"])
plt.title("Permutation Importance of Random Forest")
plt.xlabel("Permutation Importance")
plt.tight_layout()
plt.show()
That code gives us the below plots - the first being for Feature Importance and the second for Permutation Importance!
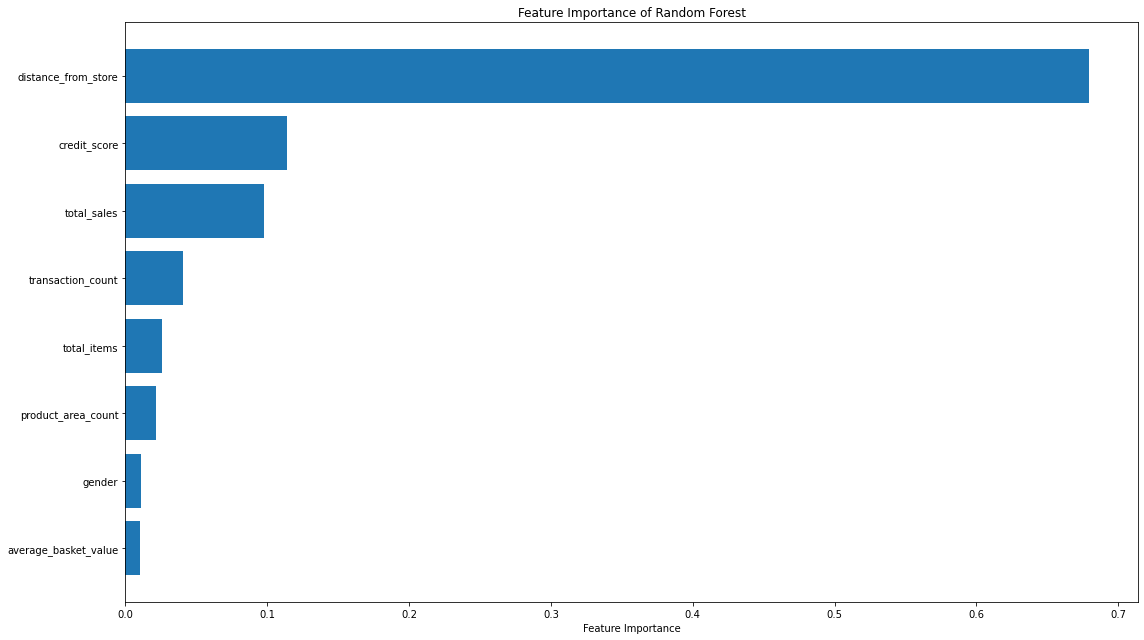
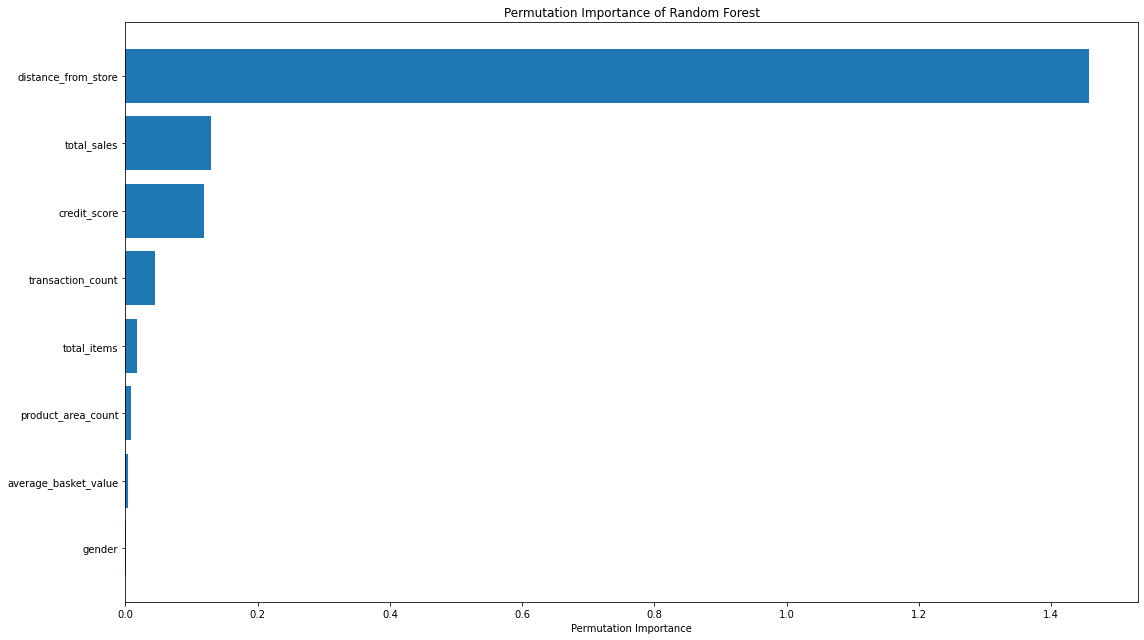
The overall story from both approaches is very similar, in that by far, the most important or impactful input variable is distance_from_store which is the same insights we derived when assessing our Linear Regression & Decision Tree models.
There are slight differences in the order or “importance” for the remaining variables but overall they have provided similar findings.
Modelling Summary
The most important outcome for this project was predictive accuracy, rather than explicitly understanding the drivers of prediction. Based upon this, we chose the model that performed the best when predicted on the test set - the Random Forest.
Metric 1: Adjusted R-Squared (Test Set)
- Random Forest = 0.955
- Decision Tree = 0.886
- Linear Regression = 0.754
Metric 2: R-Squared (K-Fold Cross Validation, k = 4)
- Random Forest = 0.925
- Decision Tree = 0.871
- Linear Regression = 0.853
Even though we were not specifically interested in the drivers of prediction, it was interesting to see across all three modelling approaches, that the input variable with the biggest impact on the prediction was distance_from_store rather than variables such as total sales. This is interesting information for the business, so discovering this as we went was worthwhile.
Predicting Missing Loyalty Scores
We have selected the model to use (Random Forest) and now we need to make the loyalty_score predictions for those customers that the market research consultancy were unable to tag.
We cannot just pass the data for these customers into the model, as is - we need to ensure the data is in exactly the same format as what was used when training the model.
In the following code, we will
- Import the required packages for preprocessing
- Import the data for those customers who are missing a loyalty_score value
- Import our model object & any preprocessing artifacts
- Drop columns that were not used when training the model (customer_id)
- Drop rows with missing values
- Apply One Hot Encoding to the gender column (using transform)
- Make the predictions using .predict()
# import required packages
import pandas as pd
import pickle
# import customers for scoring
to_be_scored = ...
# import model and model objects
regressor = ...
one_hot_encoder = ...
# drop unused columns
to_be_scored.drop(["customer_id"], axis = 1, inplace = True)
# drop missing values
to_be_scored.dropna(how = "any", inplace = True)
# apply one hot encoding (transform only)
categorical_vars = ["gender"]
encoder_vars_array = one_hot_encoder.transform(to_be_scored[categorical_vars])
encoder_feature_names = one_hot_encoder.get_feature_names(categorical_vars)
encoder_vars_df = pd.DataFrame(encoder_vars_array, columns = encoder_feature_names)
to_be_scored = pd.concat([to_be_scored.reset_index(drop=True), encoder_vars_df.reset_index(drop=True)], axis = 1)
to_be_scored.drop(categorical_vars, axis = 1, inplace = True)
# make our predictions!
loyalty_predictions = regressor.predict(to_be_scored)
Just like that, we have made our loyalty_score predictions for these missing customers. Due to the impressive metrics on the test set, we can be reasonably confident with these scores. This extra customer information will ensure our client can undertake more accurate and relevant customer tracking, targeting, and comms.
Growth & Next Steps
While predictive accuracy was relatively high - other modelling approaches could be tested, especially those somewhat similar to Random Forest, for example XGBoost, LightGBM to see if even more accuracy could be gained.
We could even look to tune the hyperparameters of the Random Forest, notably regularisation parameters such as tree depth, as well as potentially training on a higher number of Decision Trees in the Random Forest.
From a data point of view, further variables could be collected, and further feature engineering could be undertaken to ensure that we have as much useful information available for predicting customer loyalty
